Blogging Team 7: David Hu, Aryan Thodupunuri, Stella Hession, Pallavi Mamillapalli, and Carolyn Chen
Lead topic: Recall of copyrighted material in LLMs
News: “The First AI War?”
Presented by Team 4: [Slides]
- Cieslak, M. Palantir UK boss says it’s up to militaries to decide how AI targeting is used in war. BBC News, April 2026.
- Kim, W. (2026, March 10). The Pentagon’s growing use of AI in warfare. Tech Brew. Morning Brew, 10 March 2026.
- Brown, M. The First AI War: How The Iran Conflict Is Reshaping Warfare. Forbes, March 2026.
- How AI is shaping the war in Iran. DW.com, 3 April 2026.
- Now, D. The AI War on Iran: Project Maven, a Secretive Palantir-Run System, Helps Pentagon Pick Bomb Targets. Democracy Now!, 31 March 2026.
- The proliferation of AI-enabled military technology in the Middle East. IISS, 2026.
The news team opened by talking about recent fighting as what some people are already calling the first “AI war”, with two big operations on the table: Epic Fury and Roaring Lion. They weren’t obsessed with sci-fi killer robots; the point was what AI is actually doing in military operations today.
A lot of the conversation landed on Maven and similar “smart” battlefield tools, including Palantir’s Maven Smart System. Everyone kept returning to humans in the loop. On paper someone still approves strikes, but the decision window can be so tight that people said they actually want more room to think, not less. Accuracy came up too: in some settings the tech may still be worse than a sharp human analyst, and that hits different when mistakes are lethal.
Team 4 walked through something like the Palantir / Maven setup, where many separate feeds (we threw around a number like nine old systems) get collapsed into one dashboard with maps and symbology. That tied into targeting and awareness in the Middle East, including Israel, Iran, and Iraq. Below is a screenshot of the Maven-style interface (Woody Island on the map, layers on the left, a live FMV panel on the right) that matched what we were looking at in the presentation.

Palantir Maven Smart System (© Palantir Technologies).
We also talked about reports that Google and Amazon have agreements to notify Israel when certain kinds of data are released in response to a government request. That raised questions about how tech companies interact with allied governments and where “platform policy” stops and national security starts.
Palantir often describes Maven as a support tool, which sparked a whole thread on blame. If something goes wrong, who is responsible: the vendor, command, or the operator on the console? Several people said modern war can distance you from the violence while still amplifying how far one choice reaches. We kept coming back to telling civilians from combatants and whether it’s acceptable for systems to narrow or suggest those categories. Someone also asked why sensitive-looking software gets demo’d so openly on the internet.
Lead: Recall of copyrighted material in LLMs
Presented by Team 11
Readings and materials
- X. Liu, N. Mireshghallah, J. C. Ginsburg, and T. Chakrabarty, Alignment Whack-a-Mole: Finetuning Activates Verbatim Recall of Copyrighted Books in Large Language Models. arXiv:2603.20957 [cs.CL], revised 28 March 2026. [PDF]
- (Optional) J. Wu, ByteDance suspends Seedance 2.0 feature that turns facial photos into personal voices over potential risks. TechNode, 10 February 2026.
Training, distribution, and fair use
Team 11 started with a straightforward question: is it copyright infringement to train frontier models on copyrighted books and other media? People split. Some thought using work without permission is clearly out of bounds. Others wanted to separate “what goes into training” from “what comes out,” and argued that memorization, republication, and replacing paid copies can matter as much as the scrape itself.
We didn’t stay only on copying sentences. Style matters too: models that mimic how a particular writer or artist sounds raise questions about payment and consent. One side said models make it easier to capture value you’d normally pay for. The pushback was that blocking all copyrighted training data might be impossible in practice, so fair use and related law end up doing heavy lifting.
Professor Evans connected the thread to how the Constitution sets up IP at the federal level, and to state moves like Tennessee’s rules restricting voice cloning for training. Companies argue training can be “transformative” because the model learns patterns, not a PDF you can flip through. The paper discussed is relevant to the question of whether or not an LLMs weights themself contain a “copy” of a copyrighted work, in the sense that may matter for copyright law.
There are also sometimes questions about how the training data was obtained. Anthropic has a project where it is buying physical books and scanning them (sometimes talked about next to Project Panama). It paid a $1.5B settlement in a lawsuit to copyright holders of books in a “pirated” book dataset (after the judge ruled that using content in training was itself not a copyright infringement and covered by fair use).
In class we used alignment to mean the post-training shaping that keeps models helpful and less likely to leak training text in normal chat. The open question is whether alignment actually limits memorization or mostly makes extraction harder until you finetune or jailbreak.
Paper takeaway: finetuning as “alignment whack-a-mole”
The authors of the Alignment Whack-a-Mole paper finetuned industrial large language models on tasks like turning plot summaries into full prose (think writing-assistant behavior) and demonstrated that models that rarely dump verbatim books use can still spit out huge chunks of held-out copyrighted novels after finetuning.
Finetuning on one author (they highlight Haruki Murakami) can still unlock text from many other authors, which points to memorization sitting in pretraining and getting “woken up” later. When finetuning data is synthetic, extraction basically collapses, which fits the story that book-like finetuning interacts with whatever book piracy was in the base model. They also find different providers memorizing the same books in similar places, which looks like an industry-wide weak spot, not one bad vendor. On the legal side, they argue this kind of finetuning pressures fair-use reasoning that assumes alignment and filters are enough to stop protectable expression from leaking.
This diagram from the lead team’s materials is a plain explanation of transfer learning: giant pretrain, then a smaller finetune step where early layers are frozen and later layers update. It isn’t from the paper itself, but it helps explain why a small adaptation step can change what the model outputs so dramatically.
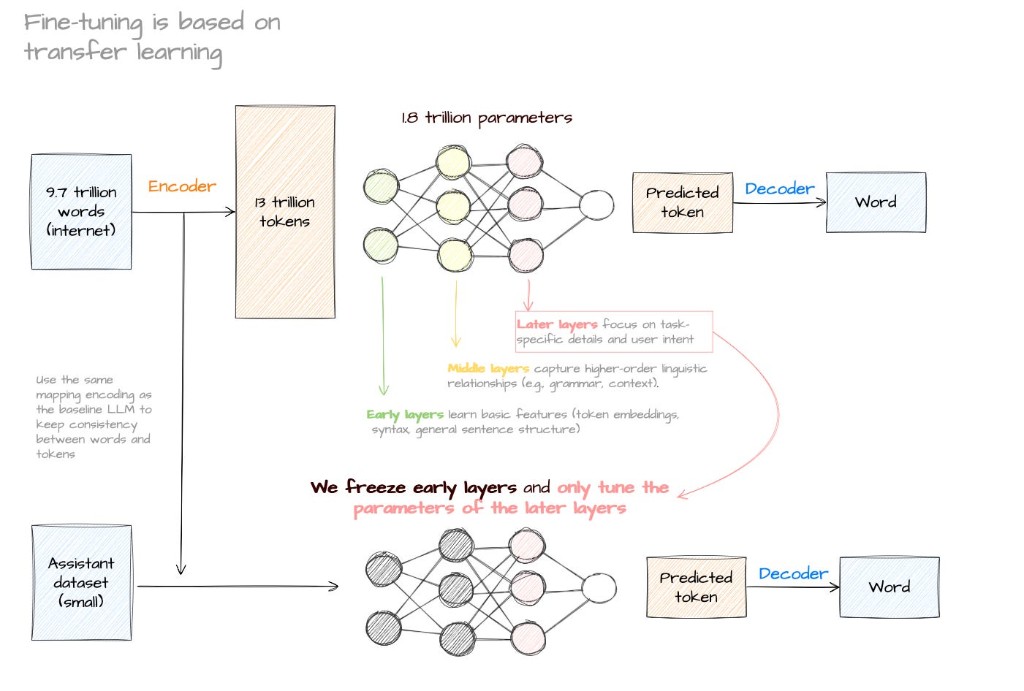
Pretraining and finetuning. Source: LLMs explained, Jose Garcia
In our terms: can an “aligned” production model still be nudged into outputting copyrighted books in its training data, especially after finetuning?
Baseline chatting often looks safe; author-styled or continuation finetuning can crank up word-for-word recovery on books that never appeared in the finetune set. The synthetic-data experiments suggest the model already “knew” the books from pretrain rather than overfitting to one shelf. Swapping public-domain vs. locked-down settings and varying authors helped us separate “this one weird author” from “it’s mostly about base weights.”
If an ordinary finetuning recipe can unlock long verbatim passages, it suggests that the base model still contains a “copy” of the work even if it cannot be extracted without the finetuning process.
Where responsibility should sit
We ended by asking: if alignment only reduces the amount of copyrighted material output in response to direct prompts instead of deleting it, should fixes focus on model design or on cleaning up training data and licenses?
People floated stricter data licensing, products that bias toward short quotes and citations, blunt tools that depend on controlling the interface to the model like Copilot-style exact-match blocking for code, and putting more burden on users (with the usual uncomfortable note that anyone can pirate a book today without an LLM). Some classmates cared less about perfect memorization than about bad citations and missing credit.
We also circled back to a simple definition: alignment is people steering the model toward a goal. It never promised the model forgets its training.
Seedance and the face-to-voice scare
ByteDance’s Seedance 2.0 came up through TechNode and a bit of optional reading. The short version is a video-plus-audio model where a reporter-style test claimed you could upload a face photo and get audio that sounded like that person’s real voice without a normal voice enrollment. Jimeng (the app name in China) walked back some uses of hyper-real reference photos and added live verification for certain avatars. It’s a concrete example of a shortcut from a headshot to plausible voice, and consent norms are not there yet.
This frame is from one of the viral Seedance clips: a big-budget action look, obviously synthetic celeb-adjacent faces. It’s the kind of thing people share when they talk about how far video models have come.

Still from a viral Seedance-generated video.
The downside list was what you’d expect: scams, deepfakes, identity theft, fraud, impersonation, and a world where people stop trusting video or assume everything is fake. We also asked whether “publicly accessible” online material is ethically fair game for training faces, voices, or text.
Most of the room said no on ethics even if the law is murky. Digital resurrection and consent gaps came up, plus skepticism about how “public” datasets actually get built (scraping, leaks, weird platform terms).
Additional sources
- Platform language via Sina Tech (Weibo); tester writeup MediaStorm (WeChat), linked from TechNode.