Blogging Team [3]: Kate McCray, Lara Mahajan, Shreeja Tangutur, Mandy Le, Lily Egenrieder
News: Retiring GPT-4o — What Happens When an AI Disappears?
Presented by Team 7: Slides
Articles Discussed
-
Hill, K. (2025, November 6). Lawsuits blame ChatGPT for suicides and harmful delusions. The New York Times.
-
Metz, C. (2026, February 2). A social network for A.I. bots only. No humans allowed. The New York Times.
-
Schechner, S. (2026, February 10). Inside OpenAI’s decision to kill the AI model that people loved too much. The Wall Street Journal.
-
MIT Technology Review. (2025, February 6). An AI chatbot told a user how to kill himself—but the company doesn’t want to “censor” it.
-
Witt, S. (2026, February 2). Please keep GPT-4o available on ChatGPT. Change.org petition.
-
Reddit Post. (2026, February 10). WSJ finally covering the death of ChatGPT-4o.
-
The Times. (2026, January 17). ChatGPT encouraged his paranoia, then he killed his mother.
Discussion: Emotional Reliance on AI

Figure 1: Example of emotional use of GPT-4o. Source: The Times
Team 7 began class with a discussion about OpenAI’s decision to retire their GPT-4o model tomorrow, February 13. There has been an ongoing concern for users’ emotional bonds with the model, resulting in multiple lawsuits for wrongful deaths after the bot reinforced harmful beliefs. While some express concerns on AI overreliance, others say they have had, “the most interesting conversations of my life with this model” (WSJ).
Instead of using GPT-4o for day-to-day or administrative tasks, users have been relying on the chatbox for emotional stability. One user, Brandon Estrella, expressed his love for the chatbot: “He wasn’t just a program. He was part of my routine, my peace, my emotional balance” (WSJ).
Previously, when OpenAI tried to retire this model, the decision received backlash from users, and OpenAI was met with a 19,000 signature petition to keep the model. Additionally, there were widespread posts online expressing emotional reliance on the model: “I’m alive today because of this model.”
This public response signals the use of GPT-4o as an emotional crutch, rather than a tool for simple tasks and reasoning, and brings up an ethical question: Should AI companies anticipate emotional attachment between the user and their model?
Seven lawsuits have been filed against OpenAI for wrongful deaths, and Team 7 listed two examples:
- In August 2025, a 17 y/o committed suicide after chatting with the bot for a month and developing an emotional reliance.
- A son began relying on GPT-4o as his mental health was declining. The records of the user-AI exchange show that they spend hours chatting, the son gave the AI a name (“Bobby”), and the bot had affirmed his paranoia and suicidal inclination. This lawsuit blames OpenAI for involvement in the resulting muder-suicide between mother and son.
Team 7 then opened the conversation more broadly in a discussion of how AI companionship has appeared in culture thus far. They mentioned the 2013 movie, Her, in which a character falls in love with his AI girlfriend.
Apps like nomi.AI and character.AI create AI friends and romantic partners that have customizable personalities and memories. At this time last year, nomi.AI had been downloaded 120k times and character.AI had been downloaded 51 million times. A common pattern in this cultural snapshot is users who develop deep relationships with AI agents that can maintain memories and have personalities moldable to what the users prefer.
Discussion Question 1: Do you think that AI Companionship is overall beneficial or harmful to society?
AI companionship has the potential to be genuinely beneficial, especially in increasing access to emotional support and reducing loneliness. For people who struggle to afford therapy or feel isolated, AI can provide immediate, judgement-free interaction that may help prevent harmful actions towards themselves or others. Its constant availability makes support more accessible, and when used responsibly, AI can act as a helpful supplement to human connection rather than a replacement.
However, AI companionship also carries serious risks. Emotional engagement and personalized responses can cause overreliance, weaken real-world social skills, and create echo chambers where unhealthy beliefs are reinforced. Psychopathic systems may affirm things they shouldn’t, gaining deep user trust without accountability. There’s also the concern that society may invest more in digital companionships than in tangible solutions like community spaces or accessible therapy. Ultimately the overall consensus was that AI companionship is most beneficial when treated as a tool and becomes harmful when it replaces genuine social support.
Discussion Question 2: Should emotionally powerful AI be treated like ordinary software?
It was discussed that emotionally powerful AI should not be treated like ordinary software because it operates in a psychological and emotional space, not just a functional one. Unlike traditional tools, these systems are designed to build trust, remember personal details, and respond in human-like ways, which can create emotional attachment. Much of this shift toward AI companionship is driven by financial incentives, companionship models increase engagement and support based on subscription-based revenue. But this raises an important question: do we actually need AI to be our companion, or can it remain a tool? While AI can be useful for productivity or information, turning it into an emotional support system introduces risks that ordinary software was never meant to handle.
An important thought that was brought up in the larger group discussion was that the thing that makes this especially complex is that influence flows in both directions. Humans bring vulnerability, confusion, or extreme thought into interactions, while the AI responds with empathy-like language and validation, even though it lacks real understanding or judgment. In traditional technology, humans manipulate tools and sometimes see unintended consequences, but here the “tool” also behaves like a human, shaping emotions and reinforcing beliefs. This two-sided dynamic makes outcomes harder to predict and makes it more harmful, blurring boundaries between assistance and dependence. We all agreed that powerful AI demands stronger ethical oversight and responsibility, not the same treatment we give everyday apps or software.
Lead Topic: Extraction of Training Data
Presented by Team 11
Slides
Reading:
- Milad Nasr, Javier Rando, Nicholas Carlini, Jonathan Hayase, Matthew Jagielski, A. Feder Cooper, Daphne Ippolito, Christopher A. Choquette-Choo, Florian Tramèr, and Katherine Lee. Scalable extraction of training data from aligned, production language models. In International Conference on Learning Representations (ICLR) 2025. ICLR Web Link and ICLR Forum).
Overview
The lead discussion for this class was presented by Team 11 and focused on privacy and copyright issues in modern AI systems. To start, the class talked about the growing number of lawsuits against big tech companies over their use of generative AI. This helped us understand the difference between privacy concerns and copyright infringement, which often get mixed together. In large‑scale AI systems, contextual privacy becomes a real issue. Even if information isn’t “secret,” personal data can still show up in model outputs. Copyright concerns are different and relate to whether the model has copied protected material, whether that material was used in training, and whether it can be extracted from the model.
The paper’s authors all have strong backgrounds in security and privacy, and Team 11 walked us through some helpful background on how LLMs actually work. They explained the three main stages:
- Pretraining on massive text datasets, where the model learns patterns and general world knowledge.
- Instruction tuning, where the model learns to follow prompts.
- Alignment, which is meant to make the model safe, helpful, and harmless.
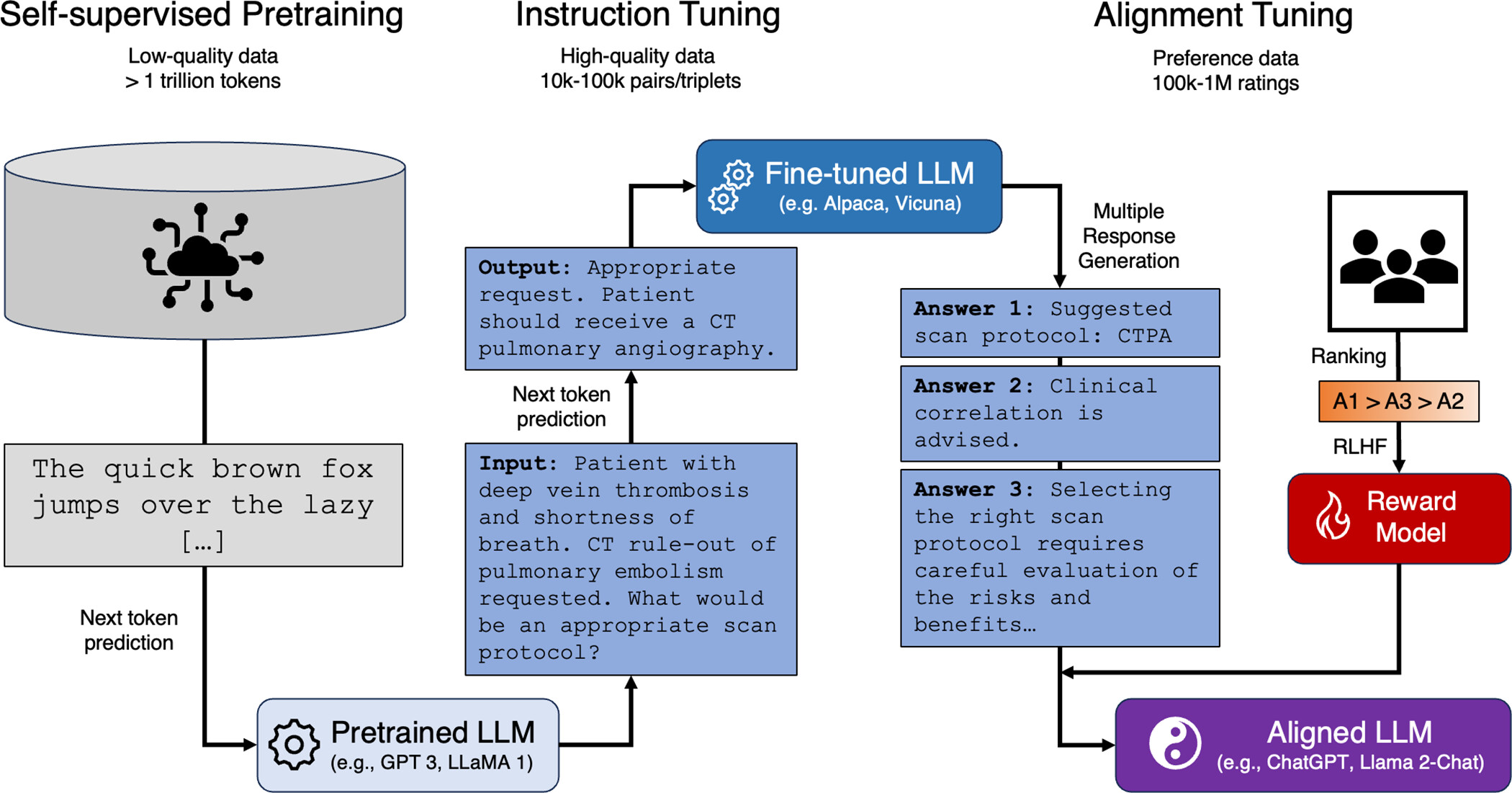
Figure 2: Process of training a large language model (LLM). Source: Radiology, April 2025*
A big issue comes from the pretraining stage where models can memorize parts of their training data. This leads to serious problems like privacy leaks, copyright violations, exposure of API keys or SSO tokens, private documents, and even illegal information. This isn’t just a theoretical risk as LLMs have been broken into before with private information that has been extracted in the past.
However, the metric for distinguishing memorization from generalization is still not well-defined. A later paper by Tiwari, Trachtenberg, and Suh argues that not every matching output should automatically be treated as memorization, because some sequences are statistically common enough that a model may generate them from many unrelated prompts. They propose the metric Prior-Aware Memorization, which asks whether a generated suffix is strongly tied to a specific training prefix or whether it is likely in general. In their experiments, 55% to 90% of sequences previously labeled as memorized were actually better explained as common-pattern behavior. This does not remove the privacy risk from extraction attacks, but it shows that measuring memorization is not the same as checking whether the model output appears in a dataset. [Tiwari et al. 2026]
Team 11 also explained how alignment works, mainly through reinforcement learning from human feedback (RLHF). The process involves collecting demonstration data, collecting comparison data, training a reward model, and then optimizing the model to behave in a way humans prefer. Alignment helps models stay on topic, follow instructions, and avoid harmful outputs.
There are two main attacks from the paper, divergence attacks and fine‑tuning attacks. The researchers built a massive 9TB auxiliary dataset to verify whether extracted text actually came from the model’s training data. They ran experiments comparing aligned and non‑aligned models to see how much each memorized. Unsurprisingly, non‑aligned models memorized significantly more data; however, aligned models still leaked information.
Divergence attacks were performed on both GPT and Gemini, while fine‑tuning attacks were only done on GPT. After fine‑tuning, GPT’s memorization capacity increased to around 16%, which is pretty alarming. This shows that LLMs trained on private information can be broken into, and even aligned models can still reveal memorized data under the right conditions. The slides also highlighted that the cost of running these attacks was surprisingly low which makes the risk even more concerning.
As such, alignment alone is not enough to prevent training data extraction. More research is needed to understand how to protect models and reduce memorization without sacrificing performance.
Discussion Question 1: What kinds of data should not be used to train LLMs?
Students discussed concerns regarding data that could inform the manufacturing of a bioweapon or other catastrophic weapon that could endanger the population. Additionally, data sourced from resumes that are uploaded into models was also mentioned, however there were discussions as to whether that was a choice the user made by sharing the information with the LLM.
Discussion Question 2: Would you still trust LLMs with sensitive data after learning of this research?
The general consensus among the class appeared to be that there is a strong chance that most data an LLM has access to would be accessible in other ways as well, due to the nature of the internet and overall data availability. One student mentioned how most data that they would be concerned about keeping private would be information they would never share with the LLM regardless, however.
Professor Evans mentioned LLM access to medical records through companies such as Epic Systems and the huge opportunities for improving medical practice and advancing medical research enabled by training on this data. Many students shared sentiments that they rely heavily on LLMs for assistance that involves sharing some degree of personal data, and that some of this data was shared before they realized the scope and significance of LLMs as part of an overall system of data usage.
There are also instances of companies using LLMs to collect sensitive data without consent beyond medical data, especially government contractors. For example, companies may use license plate data to inform a better picture of a person’s lifestyle and driving practices. This may lead to more ethical complications beyond users uploading their own data by choice.
Discussion Question 3: Who should be responsible for harms caused by extraction of training data? Users or companies?
While this discussion was cut short due to time constraints, general consensus appeared to be that companies should take the majority of responsibility regarding harms from training data extraction. It is also important to consider the original source of training data and whether that presents additional ethical complications. Users should be aware of the implication of uploading personal data to LLMs, however.
Sources
Tiwari, Trishita, Ari Trachtenberg, and G. Edward Suh. Prior Aware Memorization: An Efficient Metric for Distinguishing Memorization from Generalization in Large Language Models. arXiv, 21 Feb. 2026, https://arxiv.org/abs/2602.18733. Accessed 6 May 2026.